

Software Architecture
아키텍쳐(Architecture)라고 하면 전체적인 구조를 뜻한다.
하드웨어 아키텍쳐라고 하면 컴퓨터 구조, 하드웨어 구조를 말한다.
소프트웨어 아키텍쳐의 경우에는 큰 그림(big picture)으로 이해하면 쉽다.
Big Picture
이 그림을 다시 한 번 보자.
Process Activities 라는 글에서도 봤던 그림이다. ▼

이 그림의 정체는 Android OS의 소프트웨어 아키텍쳐다.
위로 올라갈수록 소프트웨어 레벨이고, 아래로 내려갈수록 하드웨어 레벨이다.
즉, 우리가 흔히 말하는 High-level과 Low-level의 개념이다.
이렇게 위에서부터 아래까지 전체 서브 시스템들이 뭐가 있는 지 파악하기 쉽게 해주는 것이 소프트웨어 아키텍쳐이고, 전체적인 그림으로 Big Picture라고 부른다.
Drawing Architecture
조금 다르게 해석하면, 아키텍쳐를 그린다는 것은 서브 시스템들을 찾아서 나열하는다는 것으로도 볼 수 있다.
하지만 단순히 나열한다고 아키텍쳐 드로잉이 끝나지는 않는다.
서브 시스템들을 찾고, Layering, Partitioning, 그리고 MVC를 통해 찾은 서브시스템들을 분류해야한다.
그러면 가장 먼저 해야하는 것이 서브 시스템을 찾는 것이므로 서브 시스템에 대해서 알아보자.
서브 시스템(Subsystem)
서브 시스템은 공통된 속성을 가지는 것들을 그룹화한 것을 말한다.
예를 들면, HCI 서브 시스템이라고 하면 UI와 관련한 것을 다 모아놓은 시스템을 말한다.
Data Management 서브 시스템이라고 하면, DB나 파일 관리하는 것들을 모은 것을 말한다.
조금 구체적으로 들어가보면, Campaign Management 서브 시스템은 Campaign과 관련된 기능을 다 모은 것을 말한다.
서브 시스템의 범위가 무조건 넓고 일반화 되어있을 필요는 없다.
큰 하나의 시스템을 서브 시스템으로 나누는 이유
전체를 보는거랑 나눠서 보는거랑은 차이가 굉장히 크다.
큰 문제를 해결하는 기본 원칙인 Devide and Conquer, 분할 정복을 생각해보자.
큰 것을 여러 개로 나눠서 하나씩 해결하다보면 전체가 완성이 된다. ▼
그러므로 여기서 나눈다는 의미는 복잡도를 낮춘다는 의미와도 일맥상통한다.
그런데 그렇다고 아무렇게나 막 나누면 안된다.
나눌 때 의존성을 줄이며 나눠야 한다.
즉, 모듈화를 하면서 나눠야 한다는 말이다.
서로 최대한 독립적으로 나눠야한다. ▼
최대한 독립적으로 나누면 좋은점은 개발 단위가 줄어든다는 것이다.
즉, 만들기 편해진다는 말이다.
그리고 단위를 줄일 수록 재사용성을 최대화할 수 있다.
이를 통해 복잡성을 더욱 줄일 수 있다.
또한 이렇게 나눠놓으면 유지보수하기가 편해진다.
고쳐야 되는 코드의 단위가 줄어들기 때문에 수정하기도 편해진다.
전체 시스템을 고칠 필요 없이 한 부분만 고치면 된다.
이렇게 되면 portability도 증가한다.
porting은 다른 환경으로 옮기는 것을 말한다.
OS에 의존성이 없는 부분은 그대로 두고, OS에 의존적인 부분만 고치면 되기 때문이다.
Layering and Partitioning
서브 시스템으로 나누는 것에는 두 가지 일반적인 접근 방식이 존재한다.
하나는 Layering, 다른 하나는 Partitioning이다.
Layering은 추상화 단계를 조절하며 나눈다.
하드웨어로부터 얼마나 떨어져있느냐에 따라 추상화의 단계가 달라진다.
레이어링. 추상화 레벨이 다름. 하드웨어로 부터 얼마나 떨어져있느냐에 따라 추상화 레벨이 다름.
Partitioning은 같은 기능들끼리 모으는 것을 말한다.
주로 전체 시스템에서 같은 기능들끼리 모으기 보다는 한 레이어에서 같은 기능들을 모은다.
Layering
Layering에는 두가지 방식이 존재한다.
하나는 Closed architecture, 다른 하나는 Open architecture이다.
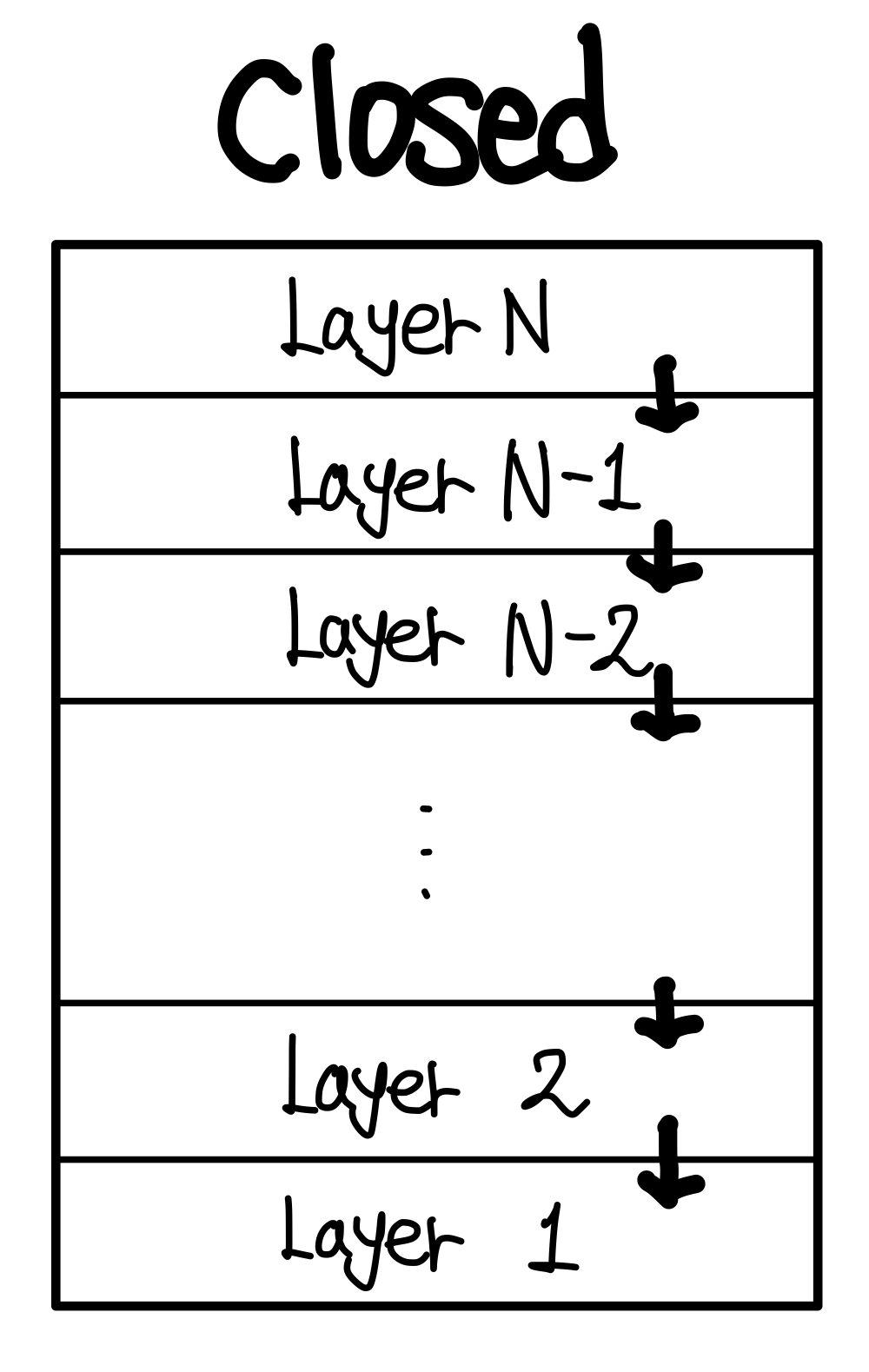
Closed Architecture
Closed Architecture는 자신보다 낮으면서 인접한 레이어 하나와만 소통한다.
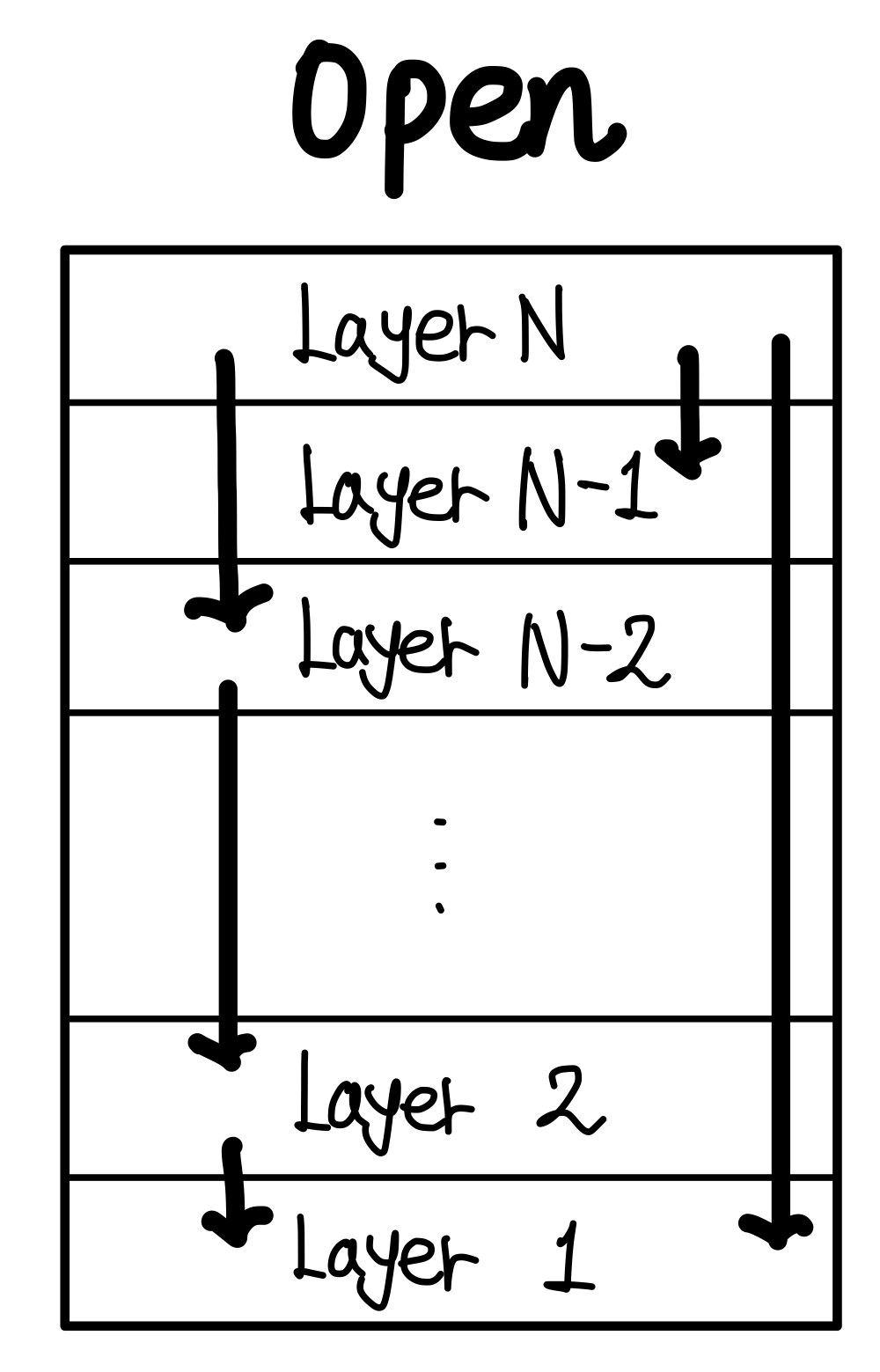
Open Architecture
Open Architecture는 레이어 간의 소통에 제한이 없다.
디자인 관점
그렇다면 디자인적 측면에서는 둘 중 어느게 좋을까?
디자인적인 측면에서는 일반적으로 Closed가 Open보다 좋다.
디자인에서 가장 중요한 것은 Encapsulation이고, 의존성을 줄이는 것이다.
Closed의 경우, 영향을 주는 것을 최소한으로 할 수 있다.
다른 레이어는 신경쓰지 않고 현재 레이어의 위와 아래만 신경쓰면 되기 때문이다.
하지만 Open의 경우, 영향을 주는 것에 제한을 둘 수 없다.
다른 레이어와 모두 소통이 가능하기에 영향을 주는 것도 많아지고, 주는게 많아지면서 당연히 받는 것도 많아진다.
그래서 다른 레이어들에 대해서도 신경을 써야하고, 이렇게 신경을 쓴다는 것은 의존성이 높아진다는 것을 의미한다.
closed에서는 Layer N은 N-1만 알면 되고, N-2부터는 몰라도 된다.
하지만 open은 Layer N이 N-1개의 레이어를 모두 알아야 한다.
결국 자신을 포함한 N개의 레이어를 알아야 한다.
퍼포먼스 관점
그렇다면 open은 단점만 있는 바보같은 방식일까?
꼭 그런 것만은 아니다.
퍼포먼스 관점에서는 Open이 훨씬 좋다.
소통의 시간을 줄일 수 있기 때문이다. ▼
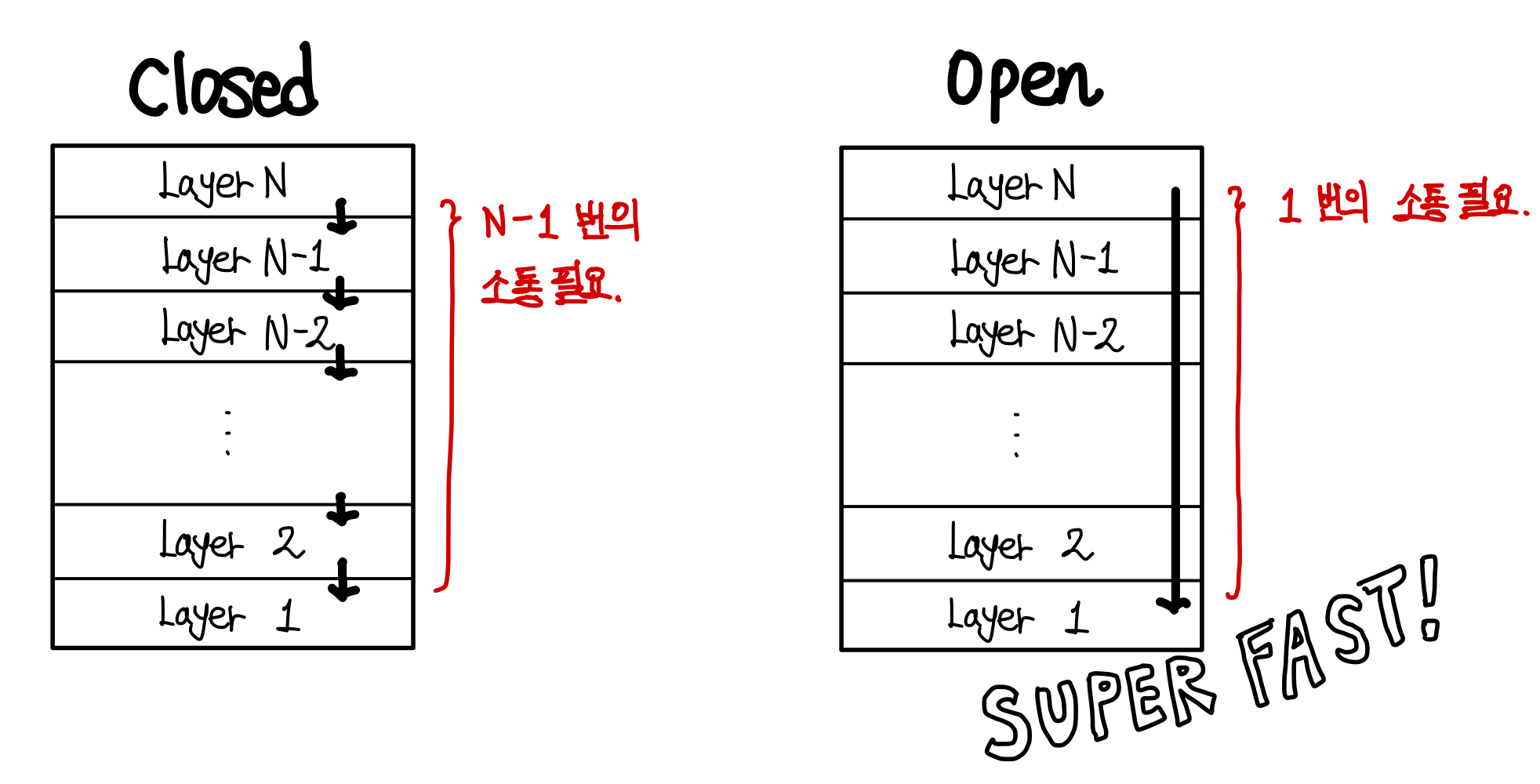
Layer N에서 Layer 1로 메세지를 보낸다고 하면, Closed Architecture에서는 N-1번의 소통이 필요하다.
하지만 Open Architecture에서는 단 1번의 소통으로 메세지를 보낼 수 있다.
프로그램 코드 길이
그렇다면 프로그램 코드 길이는 둘 중 어떤 게 더 compact할까?
이는 퍼포먼스의 관점과 유사하다.
Closed Architecture는 N - 1 개의 인터페이스를 정의해야한다.
하지만 Open Architecture는 필요한 것만 정의하면 된다.
상황에 따라서는 Open Architecture에서느 정의해야하는 인터페이스가 많아질 수도 있지만, 일반적으로는 필요한 것만 정의하기에 더 적은 인터페이스만 정의해도 된다.
종합
둘을 종합해보면 아래와 같다.
| Closed | Open |
|
|
"그렇다면 뭐가 됐건 구조가 중요하니까 Closed Architecture가 모든 면에서 좋은 거 아닌가?"
항상 그런 것만은 아니다.
만약에 성능이 엄청나게 중요하다면 Open Architecture도 고려해야한다.
모든 상황에서 좋은 Architecture는 없기에 둘의 장단점을 잘 이해하고 있다가 상황에 맞춰 사용하는 판단력이 중요하다.
물론 이렇게 말했지만 일반적으로는 Closed Architecture가 구조적으로는 Open보다 훨씬 좋다.
예시 - OSI
OSI 7 Layer는 대표적인 Closed Architecture다. ▼

우리가 네트워크 프로그래밍 중 소켓 통신을 하겠다고 하면 IP와 Port만 알면 된다.
Trasnport와 Pysical 레이어에 대해서 알 필요가 없다.
아래 레이어들은 ‘당연히 잘 동작하겠지’ 하는 마음으로 사용할 수 있다는 것이다.
하지만 Open Architecture였다면 아래 레이어에 대해서도 다 알고 있어야한다.
그러면 '사용성 측면에서도 Closed Architecture가 더 좋네' 할 수 있지만, 만약에 최적화와 같은 성능에 직결된 문제를 해결하기 위해서는 Open과 같은 방식으로 직접 제어하는 게 좋을 수 있다.
우리는 여기서 하나의 진리를 알 수 있다.
"일반적인(Generic) 것은 사용하기엔 좋지만 성능은 별로다."
라는 진리를 말이다.
MVC
위와 같이 Layering으로 나누고 Partitioning으로 잘 엮으면 Architecture가 완성이 되는데, 유저와 소통이 많은 시스템에서는 해결을 못하는 부분도 생긴다.
Layering과 Partitioning은 현실세계의 것들을 반영하기 힘들 때가 있다.
그래서 이런 문제를 해결하고자 나온 것이 MVC 이다.
예제 상황
그러면 어떤 상황에서 MVC를 적용할 수 있을까?
윈도우에서 탐색기를 5개를 띄우고 모두 동일한 파일을 보고 있다고 하자. ▼
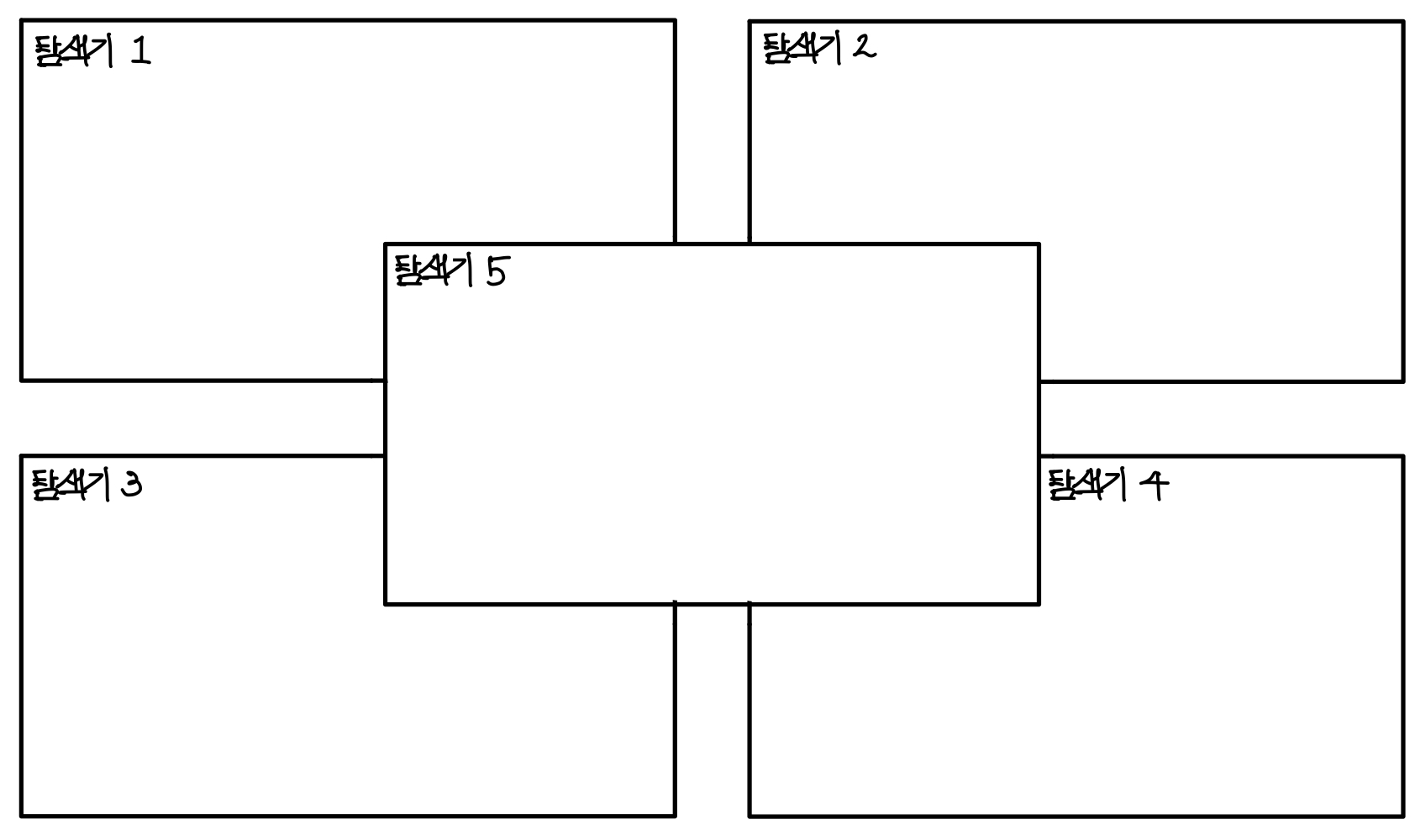
띄운 5개의 탐색기 중, 어떤 탐색기에서 특정 폴더 하위에 폴더를 만들었다고 해보자. ▼
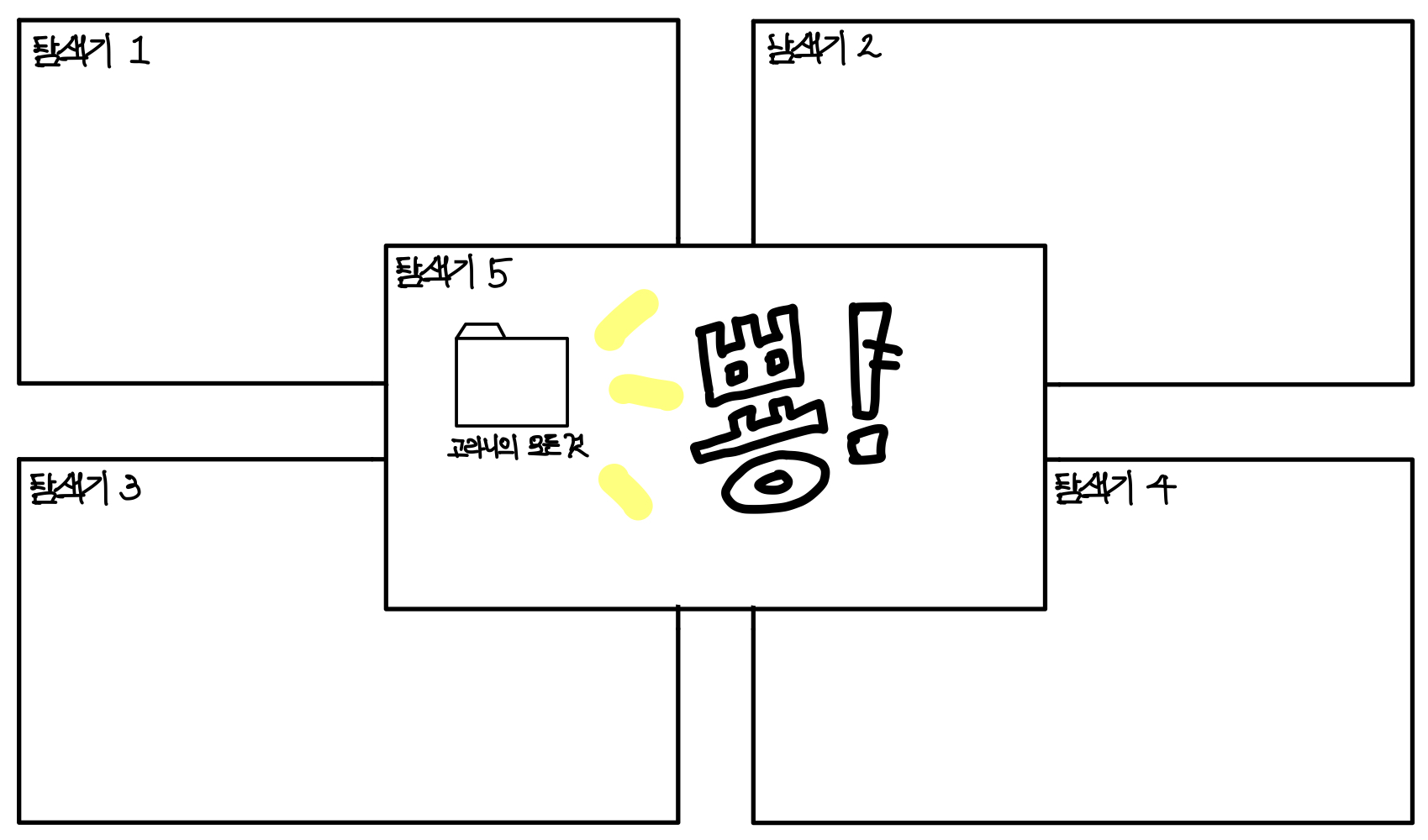
그럼 어떻게 될까? 아주 당연하게도 나머지 탐색기에서도 다 보여야한다. ▼
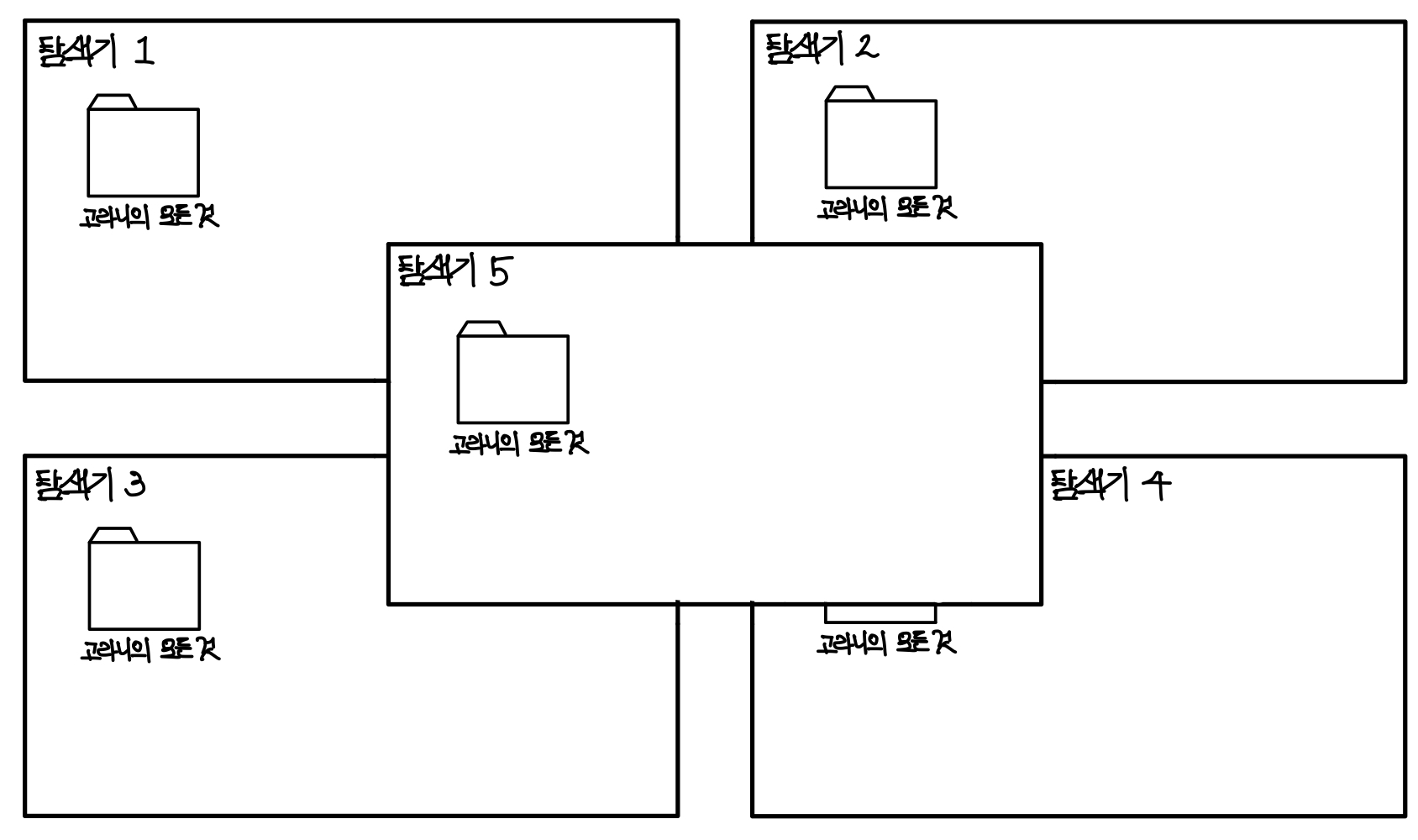
그것이 사용자들이 예측하는 것이고, 이를 Consistency라고 한다.
하지만 Layering과 Partitioning 방식으로는 이를 표현할 수 없다.
Consistency한 관계를 표현하는 것과 그 외의 여러 문제들을 해결하고 표현하는 것이 불가능하기에 이를 MVC를 통해 해결한다.
- 같은 정보는 다른 창에서 다른 형태들로 보여질 수 있어야 한다.
- 한 화면에서의 변화는 다른 화면에서도 즉시 보여져야 한다.
- User interface에서의 변화는 쉽게 이루어질 수 있어야 한다.
- 핵심 기능은 여러 인터페이스 스타일들과 공존할 수 있게 인터페이스 자체와는 무관해야한다.
각자 구현되는건 다르겠지만, 기본적으로 이런 식으로 구성된다는걸 알면 좋다. ▼
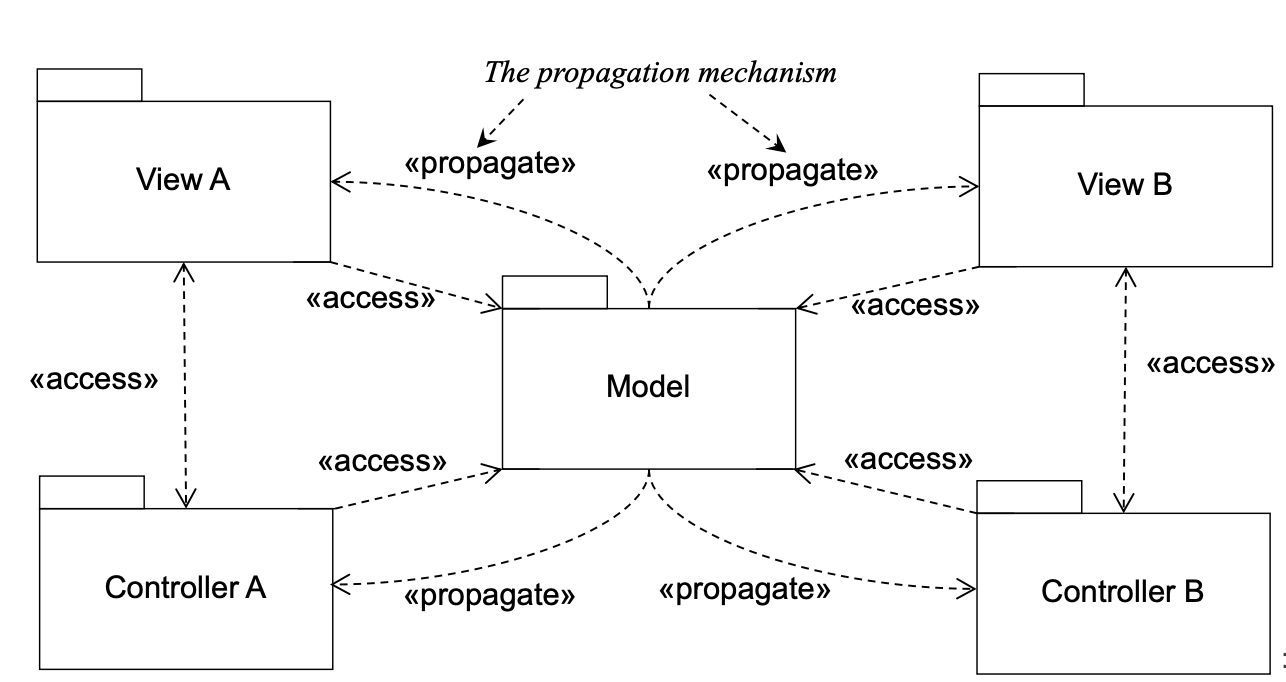
같은 정보가 여러 윈도우에 나오는걸 처리할 때 이렇게 한다고 생각하면 된다.
MVC의 구성 요소들
모델 (Model)
Entity와 같은 정보를 관리한다.
Entity하고는 다르게 자기 정보를 보여주는 뷰와 컨트롤러의 존재를 알고 있다.
기존의 Entity 클래스와 Boudary 클래스, Control 클래스의 관계를 생각해보면 해당 관계에서는 Control 클래스만이 둘의 정보를 알고 있다.
하지만 모델의 경우, Entity와 비슷하지만 Entity와는 다르게 나머지 둘(뷰와 컨트롤러)의 존재를 알고 있다.
모델에 업데이트가 생기면 기존에 알고 있던 뷰와 컨트롤러에게 정보를 알려준다.
뷰 (View)
정보를 보여주는 특정 스타일과 포맷을 말한다.
뷰는 모델에서 데이터를 가져오고, 정해놓은 특정 스타일과 포맷대로 정보를 화면에 보여준다.
똑같은 정보를 띄워주는 다른 뷰에서 변화가 일어나면 스스로도 정보를 바꿔 보여준다.
컨트롤러 (Controller)
스스로와 연결되어있는 뷰에서 변화에 대한 이벤트가 일어났음을 판단한다.
전파 매커니즘
모델이 바뀌었다는 사실을 전파하여 뷰들이 자기 자신을 리프레쉬 하게 하는 매커니즘이다.
위의 예시를 그대로 들어보면, 탐색기에서 한 폴더를 생성한 것이 전파가 일어나야할 이벤트인 것이다.
A뷰에서 해당 이벤트가 일어났다면, A뷰에 붙어있던 컨트롤러가 이를 포착해서 모델한테 알려준다.
창이 10개 있다고 하면, 한 컨트롤러가 캐치해서 모델에게 알려주면 10개의 창에 다 전파해준다.
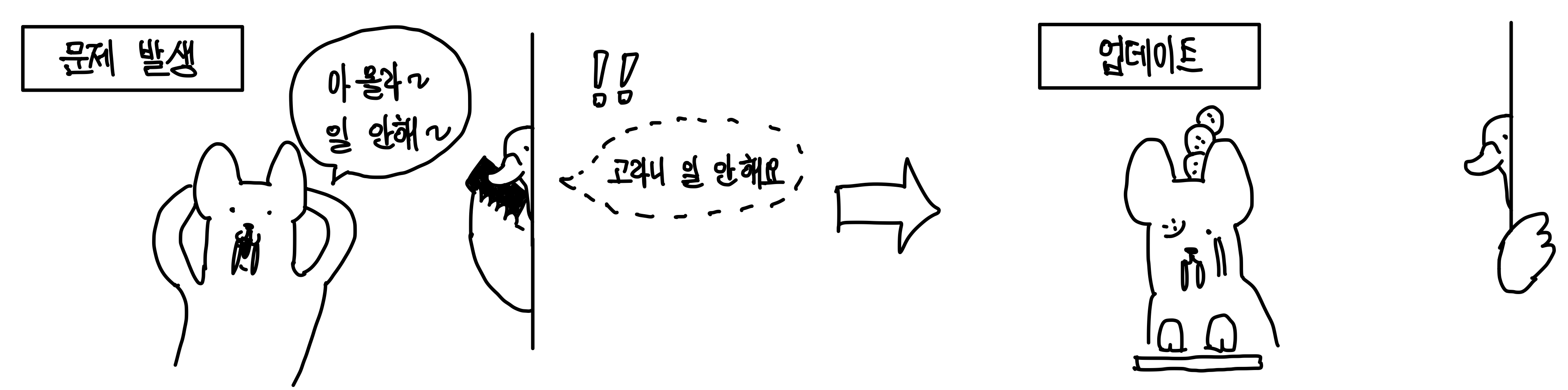
하지만 관찰한다는게 그냥 되는 것은 아니다.
관찰하려면 attach를 해야한다. ▼
attach해서 보고 있다가 문제가 생기면 알려준다. ▼
MVC의 Class Diagram
이를 Class Diagram으로 그리면 아래와 같이 그릴 수 있다. ▼
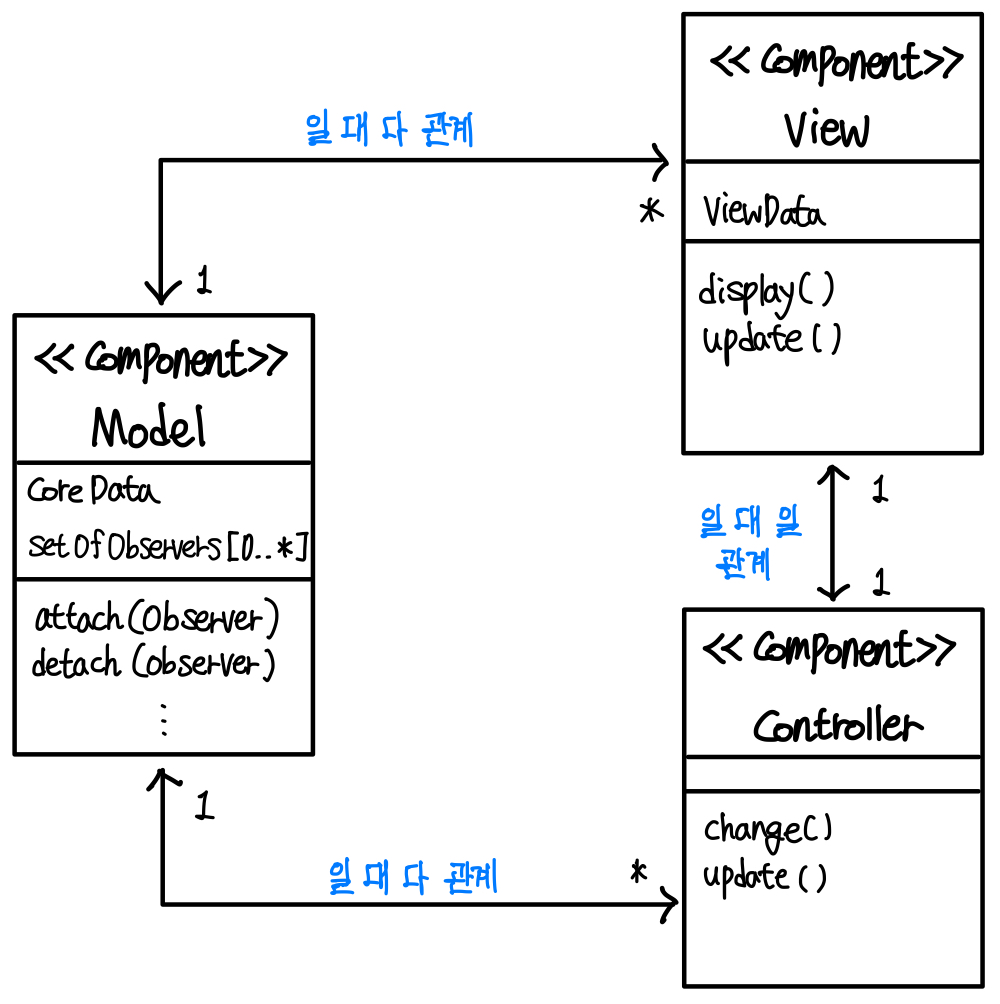
한 데이터를 여러 View에서 보여줄 수 있으므로, Model과 View는 일 대 다 관계다.
그리고 각 View에는 하나의 Controller가 있으므로, View과 Controller는 일 대 일 관계다.
그리고 이 Controller들은 Model의 존재를 알고 있으므로, Model과 Controller는 일 대 다 관계다.
MVC의 Sequence Diagram
데이터가 오가는 과정을 Sequence Diagram으로 그리면 아래와 같다. ▼
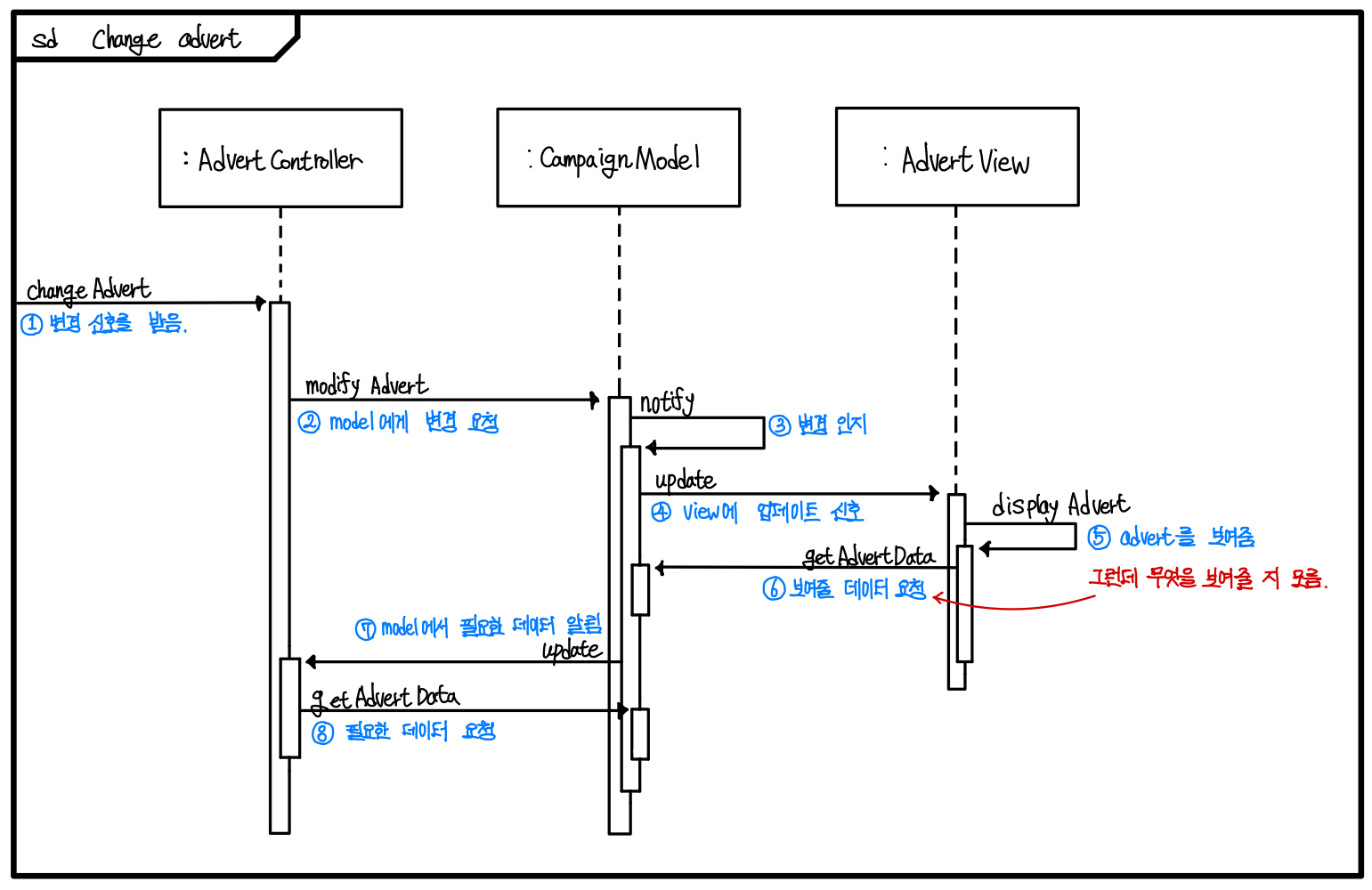
과정
- 가장 먼저 Controller가 변화한 것을 알아챈다.
- 컨트롤러는 Model에게 데이터 변경 요청을 보낸다.
- Model은 이를 감지한다.
- 그리고 Model은 View에게 업데이트 신호를 보낸다.
- 업데이트 신호를 받은 View는 데이터를 보여주려고 하는데, 무엇을 보여줄 지 모른다.
- 그래서 View는 Model에게 보여줄 데이터를 요청한다.
- Model은 이 요청을 받아 Controller에게 원하는 데이터가 있음을 알린다.
- Controller는 이 알림을 받고 Model로부터 데이터를 받는다.
'CS > 소프트웨어 공학' 카테고리의 다른 글
| 21. Testing (0) | 2024.02.04 |
|---|---|
| 20. Design Patterns (0) | 2024.02.04 |
| 18. Refining The Requirements Model (0) | 2024.02.04 |
| 17. State Machine (0) | 2024.02.03 |
| 16. Designing Boundary Classes (작성중) (0) | 2024.02.03 |



