

- 개요
- Swift로 PS를 한다는 것
- 필자의 경험
- 정보의 부재
- 어려운 입문
- 그래서 대의를 위해 정리하는거야?
- Swift 입출력
- readLine()
- 기본적인 사용법
- 여러 개 입력받기 1 : \n으로 구분되어 들어오는 입력값
- 여러 개 입력받기 2 : 공백으로 구분되어 들어오는 입력값
- 여러 개 입력받기 3 : 응용
- PS를 위한 향상된 입출력
- 라이노님의 FileIO 클래스
- 주의점 : 공백으로 입력 구분
- 주의점 : 입력의 마무리는 eof
- 반복문
- 기본적인 for문
- 역순회
- Swift의 Collection 타입들
- 배열
- 배열 선언
- 배열에 값을 넣는 방식
- append()를 사용할 때 주의점
- 배열 원소 지우기
- N차원 배열
- N차원 배열 선언
- 크기와 같이 선언
- Set과 Dictionary
- Set
- Dictionary
- Tuple
- Swift 자료구조
- Stack
- popLast() 메소드 이용
- Queue
- removeFirst() 메소드 이용
- 제거하지 않고 현재의 인덱스만 증가
- 직접 클래스 구현
- Deque
- Heap
- 아니 그래도 너무 느린걸요?
- 함수로 감싸면 빨라진다?
- 그럼 ‘왜’ 함수로 감싸면 빨라질까?
- 마치며
개요
Swift로 PS를 한다는 것
Swift로 PS를 한다는 것은 직진할 수 있는 길을 한 바퀴 돌아가거나, 평범한 길 대신에 가시 밭길을 걷거나, 그냥 스스로를 고문하는 그런 것과 비슷하다. ▼

사실 Swift로 PS를 한다고 하면 조금 말리고 싶지만, 대부분이 하고 싶어서 하는게 아니라 iOS 개발자로 취직할 때 Swift로 PS를 하지 않고 다른 언어로 하면 쿠사리를 먹는다는 정보를 듣고 하는 것임을 알고 있다.
그게 아니라 재밌어서라던가, 언어가 잘 맞는다는 이유면 굳이 말릴 필요가 없는거 같다.
약간 고통을 좋아하는 사람인가 생각한다.
“그러는 너는 왜 Swift로 하는거냐”
그야… 재밌으니까…!
필자의 경험
필자는 솔직히 PS를 잘 한다고 하기는 힘든 레벨에 위치해있다.
하지만 C++과 Swift, 두 언어로 PS를 해봤고 그 중에서도 대부분의 문제를 Swift로 해결했다. ▼
정보의 부재
Swift로 300문제가량 풀면서 느낀 것은 정보가 너무나도 없다는 것이었다.
정보가 아예 없는 것은 아니지만, 질문을 했을 때 받아주는 사람이나 잘 알려지지 않은 문제에 대한 해결책을 알려주는 사람의 수가 절대적으로 적다. ▼
어려운 입문
그렇다고 입문하기에 쉬운 것도 아니다.
거지같은 입력방식과 매우 느린 입출력 속도, 그리고 라이브러리 함수의 부재 등등 고난은 많지만 이를 모아서 설명해준 곳이 많지는 않았다.
입문하는 입장에서 이런 환경을 보면 조금 답답하고 다른 언어들에 비해 초기 투자 시간이 많이 든다면 하기가 꺼려지기도 하다.
정말 문제는 입문하는 사람들이 스스로 원해서 입문하기 보다 어쩔 수 없이 입문하는 경우가 많다는 것이다.
스스로의 선택이면 어느정도 발을 빼거나 감수를 하는게 가능하지만, 스스로의 선택도 아닌데 이런 열악한 환경에 뛰어들게 되는 상황이 안타까웠다.
그래서 대의를 위해 정리하는거야?
그건 아니다.
정리하는 핵심적인 이유는 나중에 내가 보기 편하게 정리하는 것이고, 다른 사람들이 보기 편한건 두번째다.
라고 말하니 다소 츤데레 같다. ▼
근데 1순위는 나 스스로이기에 안읽혀도 어쩔 수 없다.
잡설이 조금 길었다… 이제 시작하겠다.
Swift 입출력
readLine()
Swift의 기본적인 입출력은 readLine() 함수로 진행된다. ▼
func readLine(strippingNewline: Bool = true) -> String?
기본적인 사용법
매개변수인 strippingNewline은 필수로 들어가는 매개변수가 아니기에 일반적으로는 아래와 같은 형태로 사용이 된다.
readLine()은 String?을 반환하기에 force unwrap을 해주는 것이 좋다.
PS에서는 들어오는 형식이 정해져있기 때문이다. ▼
let str = readLine()!
"그렇다면 숫자를 받을 때는 어떻게 해야할까?"
readLine()은 기본적으로 String?을 반환하기에, 받아와서 unwrap한 String이 모두 숫자라는 전제하에 아래와 같이 형변환을 해줘야한다. ▼
let integer = Int(readLine()!)!
let double = Double(readLine()!)!
여러 개 입력받기 1 : \n으로 구분되어 들어오는 입력값
"그렇다면 여러 개의 값은 어떻게 받을까?"
readLine()은 개행문자를 기준으로 입력값의 끝을 구분한다.
이말은 즉, 정말 한 줄 씩 입력받는다는 것이다.
그래서 아래와 같은 문제의 입력을 받으려면, ▼
2750번: 수 정렬하기
첫째 줄에 수의 개수 N(1 ≤ N ≤ 1,000)이 주어진다. 둘째 줄부터 N개의 줄에는 수가 주어진다. 이 수는 절댓값이 1,000보다 작거나 같은 정수이다. 수는 중복되지 않는다.
www.acmicpc.net

이런 식으로 코드를 짜야한다. ▼
let N = Int(readLine()!)! // 입력받을 총 횟수를 정수로 입력받음
var nums = [Int]()
for _ in 0..<N { // 총 횟수만큼 입력 반복
let tmp = Int(readLine()!)!
nums.append(tmp)
}
여러 개 입력받기 2 : 공백으로 구분되어 들어오는 입력값
그런데 입력이 항상 저렇게 들어오지 않는다는 것을 알 것이다.
하지만 앞에서 언급했듯이 readLine()은 개행문자를 기준으로 입력의 끝을 받기 때문에 아래 문제에서 요구하는 입력이 들어오면 한 줄을 통째로 받게 된다. ▼
19532번: 수학은 비대면강의입니다
정수 $a$, $b$, $c$, $d$, $e$, $f$가 공백으로 구분되어 차례대로 주어진다. ($-999 \leq a,b,c,d,e,f \leq 999$) 문제에서 언급한 방정식을 만족하는 $\left(x,y\right)$가 유일하게 존재하고, 이 때 $x$와 $y$가 각각 $-
www.acmicpc.net
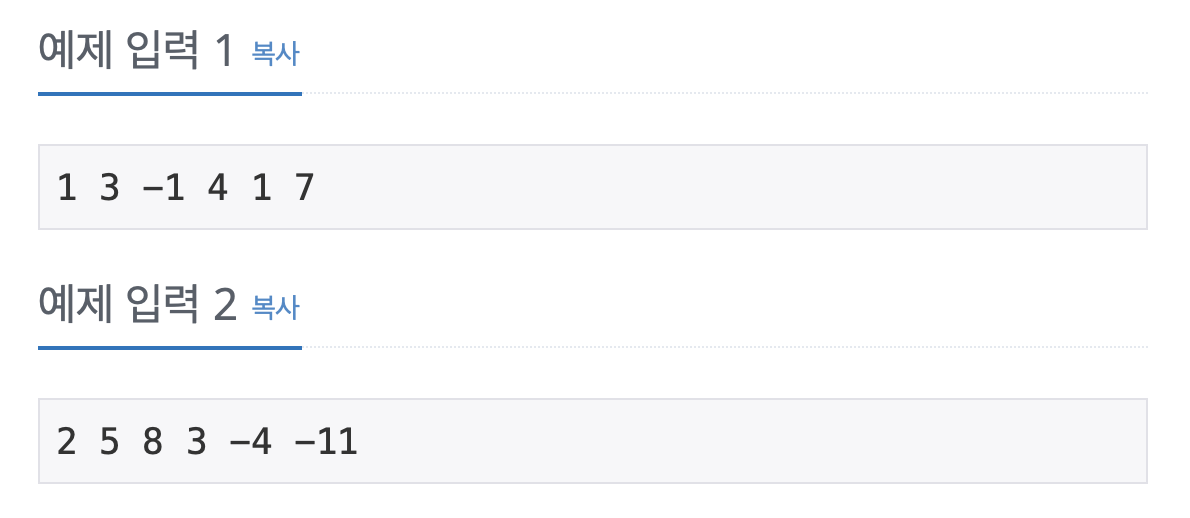
이런 경우에는 String의 split()을 사용하면 해결이 되긴 하지만, 그냥 사용하게 되면 코드가 상당히 지저분해진다. ▼
let str = readLine()!
let arr = str.split(separator: " ") // 공백을 기준으로 나눠줌
var intArr = [Int]() // 정수로 변환한 입력을 담을 배열
for i in 0..<str.count {
intArr.append(Int(str[i])!) // 변환하여 배열에 넣어주면 입력이 다 받아짐
}
하지만 이렇게 지저분한 코드를 map을 이용하면 한 줄로 받을 수 있게 된다. ▼
let intArr = readLine()!.split(separator: " ").map { Int(String($0))! }
// split해서 나온 배열을 map을 통해 각 원소들을 Int로 변환하여 새 배열에 할당해줌
이렇게 map을 통해 split으로 자른 값들을 전부 Int로 변환하여 새로운 배열에 담아 intArr에 할당할 수 있게 된다.
여러 개 입력받기 3 : 응용
"그러면 한 줄에 여러 개 입력받는게 여러 줄로 들어오면 어떡하죠…?"
아래의 문제는 입력이 한 줄에 여러 개 들어온다. ▼
1753번: 최단경로
첫째 줄에 정점의 개수 V와 간선의 개수 E가 주어진다. (1 ≤ V ≤ 20,000, 1 ≤ E ≤ 300,000) 모든 정점에는 1부터 V까지 번호가 매겨져 있다고 가정한다. 둘째 줄에는 시작 정점의 번호 K(1 ≤ K ≤ V)가
www.acmicpc.net
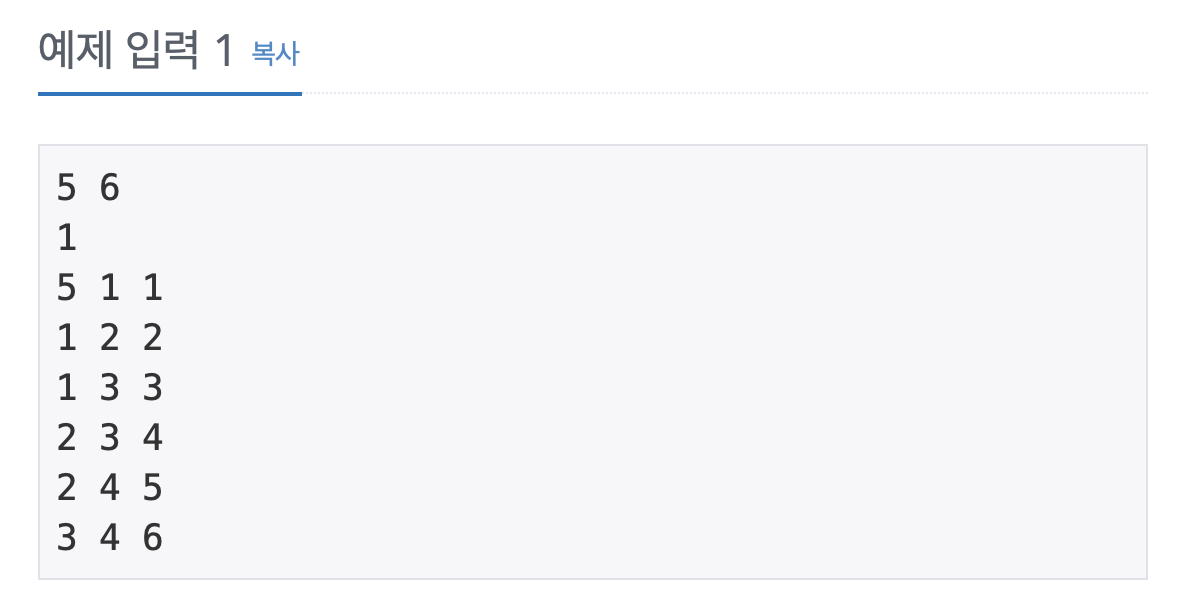
이런 문제의 경우 여러 개 입력받기 1과 2를 모두 사용해주면 된다.
그러면 코드는 아래와 같이 나온다. ▼
let VE = readLine()!.split(separator: " ").map { Int(String($0))! }
// V와 E를 배열로 한 번에 입력 받음
let V = VE[0]
let E = VE[1]
// 그리고 이를 V와 E에 하나씩 옮겨줌
let K = Int(readLine()!)!
// 시작 번호인 K는 하나의 값이니까 단일로 받아줌
for _ in 0..<E {
let uve = readLine()!.split(separator: " ").map { Int(String($0))! }
let u = uve[0]
let v = uve[1]
let e = uve[2]
// 위의 VE에서 했던 것과 같이 uve를 배열로 받고 옮겨주는 작업을 함
// 이를 E번 반복하기
}이렇게 상황에 맞게 1과 2를 적절하게 사용해주면 된다.
PS를 위한 향상된 입출력
그런데 위의 입출력 방식을 사용하게 되면 시간이 엄청나게 오래걸리게 된다.
심지어는 입출력 자체에서 시간초과가 날 때가 있다. ▼

그런데 사진을 보면 알겠지만, 입출력 시간을 무려 600ms나 줄일 수 있다. ▼

어떻게 한 것일까?
라이노님의 FileIO 클래스
입출력 시간을 600ms나 줄인 비결은 바로 라이노님이 만들어주신 FileIO 클래스다. ▼
import Foundation
// 라이노님의 FileIO
final class FileIO {
private var buffer:[UInt8]
private var index: Int
init(fileHandle: FileHandle = FileHandle.standardInput) {
buffer = Array(fileHandle.readDataToEndOfFile())+[UInt8(0)]
index = 0
}
@inline(__always) private func read() -> UInt8 {
defer { index += 1 }
return buffer.withUnsafeBufferPointer { $0[index] }
}
@inline(__always) func readInt() -> Int {
var sum = 0
var now = read()
var isPositive = true
while now == 10
|| now == 32 { now = read() }
if now == 45{ isPositive.toggle(); now = read() }
while now >= 48, now <= 57 {
sum = sum * 10 + Int(now-48)
now = read()
}
return sum * (isPositive ? 1:-1)
}
@inline(__always) func readString() -> String {
var str = ""
var now = read()
while now == 10
|| now == 32 { now = read() }
while now != 10
&& now != 32 && now != 0 {
str += String(bytes: [now], encoding: .ascii)!
now = read()
}
return str
}
}
사용 방법은 아래와 같다.
FileIO() 인스턴스를 만들고, 입력받는 타입에 맞게 readInt()와 readString()을 선택하면 된다. ▼
var file = FileIO()
let int = file.readInt()
let str = file.readString()
주의점 : 공백으로 입력 구분
FileIO()는 readLine()과 다르게 입력의 구분 기준이 \n이 아니라 공백이다.
그래서 위와 같이 여러 개를 입력받을 때 전부 공백으로 받을 수 있다.
아래와 같은 입력도 전부 readInt()하나로 받을 수 있다. ▼
주의점 : 입력의 마무리는 eof
입력을 직접 해보면 알겠지만, 아무리 엔터를 눌러도 입력이 끝나지 않는 것을 알 수 있다.
FileIO()는 입력 구분은 공백과 \n지만 입력의 끝은 eof로 받는다.
그렇기에 입력이 끝났다면 eof (맥 기준 control + d)로 마무리 해줘야 한다.
반복문
Swift의 반복문으로는 다른 언어들과 같이 while문과 for문이 있다.
while문의 경우에는 다른 언어들과 큰 차이점이 없지만, for문의 경우에는 다른 언어들과 다른 형태의 문법을 사용하고 있다.
기능도 다른 언어들과 조금 다른 형태를 띄고 있어 for문에 대해 잘 모르고 들어가면 당황스러울 수 있다. ▼
for i in 0...10 { //반복할 코드 }
그래서 이번 글에서는 for문에 대해서 집중적으로 보겠다.
기본적인 for문
Swift 문법에 대해 조금은 알고 있다면 for문 형식에 대해서도 알고 있을 것이다.
일반적으로 for문은 두가지 형식으로 사용한다.
첫번째는 수의 범위로 사용하는 것이다.
0..<10 으로 표기를 하게 되면 10은 제외하고 0부터 9까지 10번 반복된다.
0…10 으로 표기를 하게 되면 10까지 포함하여 0부터 10까지 11번 반복된다. ▼
let N : Int = 5
for i in 0..<10 { }
for i in 0...10 { }
for i in 0...N {}
이 때 i를 사용하지 않는다면, i 대신에 _를 넣어 변수를 만들지 않고 반복시킬 수 있다. ▼
for _ in 0...10 { }
두번째는 배열과 문자열을 순회하는 것이다.
아래와 같이 선언하게 되면, i와 chr에 각각 배열의 원소와 문자열의 각 문자가 담기게 된다. ▼
let arr = Array(repeating: 0, count: 5)
let str = "Hello world"
for i in arr { }
for chr in str { }
역순회
“그러면 거꾸로 순회하고 싶을 때는 이렇게 , 10…0 으로 작성하면 되겠다!”

뭔가 그럴듯 하지만, 그 결과는 컴파일 에러다.
에러 로그에서도 알려주듯이 범위는 lowerBound <= upperBound 이어야 한다. ▼

“그렇다면 역순회는 불가능한 거 아닌가요?”
stride() 함수를 이용하면 역순회를 할 수 있다. ▼
for i in stride(from: 5 , to: 0, by: -1) { }
사실 stride() 함수는 역순회만을 위한 함수는 아니다.
순회를 할 때 어디서부터, 어디까지, 어느정도 간격으로 하겠다고 명시해준다. ▼
stride (from: x, to: y, by: z)
// x부터 y까지 z의 간격으로 전진
이를 잘 이용하면 2씩 증가시켜 짝수나 홀수만 실행하는 것도 가능하고, 특정 숫자의 배수만큼만 실행하는 것도 가능해진다.
Swift의 Collection 타입들
배열
배열 선언
배열은 가장 기본적은 collection 타입이고 대부분 처음에는 아래와 같이 선언하는 법을 배울 것이다. ▼
var arr = [Int]()
// 말 그대로 아무것도 없는 Int 배열이 생성됨
이렇게 선언하면 아무것도 들어있지 않은, 크기가 0인 빈 배열이 생성된다.
Swift의 배열은 기본적으로 Vector와 같은 가변 배열이기 때문에 쉽게 늘리고 줄일 수 있다.
“그렇다면 기본 크기를 선언한 채로 만드는 것은 어떻게 할까?”
크기를 선언한 채로 배열을 만드는 방법은 아래와 같이 할 수 있다.
repeating에는 초기 값을, count에는 배열의 크기를 넣어주면 된다. ▼
var arr = Array(repeating: 0, count: 5)
// 0이 5개 기본으로 들어감
repeating에 넣는 값의 타입에 따라 배열의 타입도 결정된다.
배열에 값을 넣는 방식
Swift의 배열은 가변 배열이기 때문에 값을 넣을 때는 두 가지 패턴이 존재한다.
- 크기가 0인 배열에 배열 크기를 늘리면서 넣기
- 크기를 미리 선언하고 배열을 만든 후에 값을 넣기
// 1번 패턴
var arr = [Int]()
for _ in 0...10 {
arr.append(Int(readLine()!)!)
}
// 2번 패턴
var arr2 = Array(repeating: 0, count: 10)
for i in 0...10 {
arr[i] = Int(readLine()!)!
}
append()를 사용할 때 주의점
하지만 append()를 사용할 때는 조심해야한다. (append(_ newElement: Element))
append()의 시간 복잡도는 평균 O(1) 이지만, 최악의 경우에는 O(N)이 되기 때문이다.
보통 최악의 경우는 메모리를 재할당 해야할 때 일어난다.
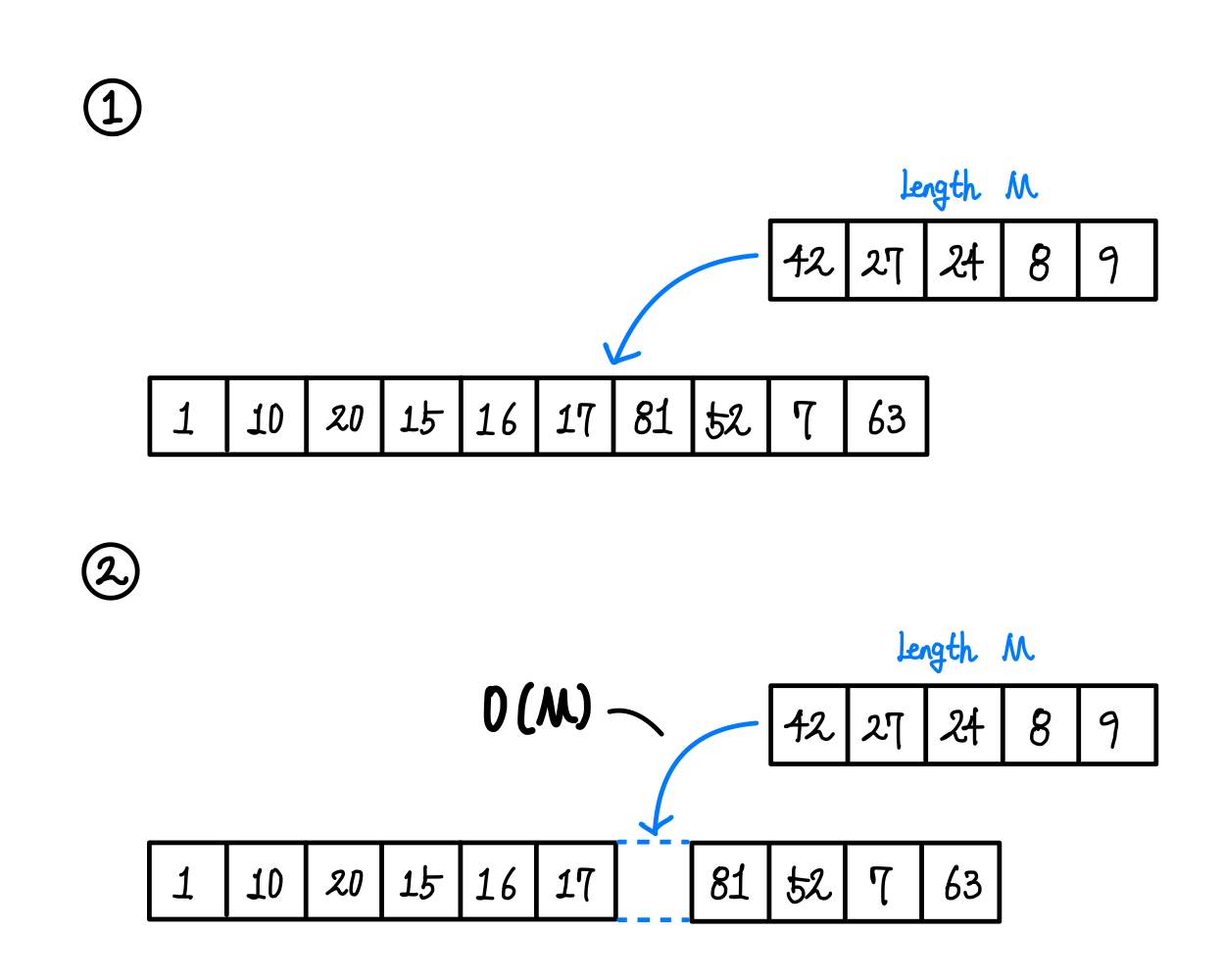
여러 값을 중간에 넣을 때도 조심해야한다.*(append(contentsOf: ))
중간에 넣을 배열의 값들을 복제하는 과정이 추가되기 때문에 시간복잡도가 O(M)이 된다. (M은 넣을 배열의 길이) ▼
![한 덩어리를 넣는거라 O(1)같지만 사실은 아니다.]
배열 원소 지우기
배열의 원소는 remove() 메소드를 통해 제거할 수 있다.
하지만 remove() 메소드는 removeLast()를 제외하고 모두 시간복잡도가 O(N)이다. (remove(at:), removeFirst())
이는 배열이 RangeReplaceableCollection을 채택하기 때문이다.
제거를 할 때, 메모리를 재조정하는게 아니라 아예 배열을 새롭게 만들어서 배열의 길이만큼 연산하게 된다. ▼

하지만 그와는 다르게 removeLast()는 O(1)이기 때문에 만약에 맨 앞의 원소를 연속적으로 지워야하는 상황이 발생하면, 위의 append()와 마찬가지로 reverse() 후에 removeLast()를 수행하는 것이 좋다.
위의 문제점을 잘 보여주는 문제 해설
백준 16234번 해설 보고 오기 ->
N차원 배열
N차원 배열 선언
기본적인 N차원 배열은 대괄호([])의 중첩으로 선언할 수 있다.
2차원 배열이면 대괄호를 2번, 3차원 배열이면 대괄호를 3번 중첩시키면 된다.
기본적인 배열 인스턴스의 선언이 [] 안에 타입을 넣는 방식인데, 이 안에 배열 타입, 예를 들면 [Int]를 넣으면 정수 배열의 배열로 선언된다. ▼
var twoDimensionArr = [[Int]]()
// 2차원 배열
var threeDimensionArr = [[[Int]]]()
// 3차원 배열
크기와 같이 선언
앞에서 보았던 Array(repeating: , count:)의 repeating 매개변수에 배열을 넣으면 크기와 같이 2차원 배열을 선언할 수 있다. ▼
var ndimensionArr = Array(repeating: Array(repeating: 5), count: 5)
// 5 * 5 2차원 배열
BFS, DFS와 같은 문제들에서 크기를 미리 설정하고 들어가는게 좋을 때가 있는데, 이럴 때 이렇게 설정하면 좋다. ▼
1260번: DFS와 BFS
첫째 줄에 정점의 개수 N(1 ≤ N ≤ 1,000), 간선의 개수 M(1 ≤ M ≤ 10,000), 탐색을 시작할 정점의 번호 V가 주어진다. 다음 M개의 줄에는 간선이 연결하는 두 정점의 번호가 주어진다. 어떤 두 정점 사
www.acmicpc.net
Set과 Dictionary
Set
Set은 아래와 같이 선언할 수 있다. ▼
var sets1 = Set()
// 인스턴스 할당
var sets2 : Set
// 타입만 할당
Set은 중복 값을 허용하지 않기 때문에 일반적으로 중복 값을 제거하고자 할 때 사용한다.
그런데 이는 배열을 Set으로 타입 변환하는 것을 통해서도 가능하다. ▼
var arr = [Int]()
print(Set(arr).count)
// 중복된 값은 모두 제거된 후 개수를 세어줌
Set의 다른 기능이 필요한 것이 아니라면, 굳이 처음부터 Set으로 선언하고 값들을 다루기 보다 배열로 선언한 후에 Set으로 변환하는게 좋을 수 있다.
Dictionary
Dictionary는 아래와 같이 선언할 수 있다. ▼
var dictionary1 = [String: Int]()
// 인스턴스 할당
var dictionary2 : [String : Int]
// 타입만 할당
Dictionary는 key : value 쌍으로 데이터가 존재하기 때문에 같은 key에 두 개의 value가 들어갈 수 없다.
이를 이용해 위의 Set과 같은 용도로 중복 값을 허용하지 않으면서, 추가로 개수를 체크하는 것으로도 사용할 수 있다.
Tuple
그런데 간혹 순서쌍을 저장하라고 할 때가 있다.
이는 2차원 배열로도 구현은 가능하지만, 순서쌍 자체의 순서를 바꾸게 되면 연산을 두번 해야하는 번거로움이 생길 수 있다.
이럴 때는 Tuple 배열을 이용하면 편리하다. ▼
var tupleArray1 = [(Int, Int)]()
var tupleArray2 = Array(repeating: [(Int, Int)](), count: V + 1)
print(tupleArray1[0].1)
// 튜플의 첫번째 원소
print(tupleArray1[0].2)
// 튜플의 두번째 원소
아래의 문제에서 이를 응용하여 저장하면 편하게 데이터를 다룰 수 있다. ▼
1753번: 최단경로
첫째 줄에 정점의 개수 V와 간선의 개수 E가 주어진다. (1 ≤ V ≤ 20,000, 1 ≤ E ≤ 300,000) 모든 정점에는 1부터 V까지 번호가 매겨져 있다고 가정한다. 둘째 줄에는 시작 정점의 번호 K(1 ≤ K ≤ V)가
www.acmicpc.net
Swift 자료구조
Swift로 PS를 하지 말라고 하는 가장 큰 이유가 바로 PS를 위한 라이브러리의 부재 때문이다.
Foundation 라이브러리와 기본 Swift 언어가 지원하는 것들은 꽤나 많긴 하다.
배열도 기본적으로 가변 배열이고, 튜플을 지원하며, 제곱이나 루트와 같은 기본적인 수학 함수들도 있다.
하지만 스택, 큐, 덱과 같은 자료구조들이 없다.
그래서 스택이나 큐, 덱을 사용하는 문제가 있다면 이를 구현해서 풀어야한다.
“이건 좀 아닌거 같은데..?”
그래도 다행인것은 기본 배열이 가변 배열에 배열을 더 편리하게 사용할 수 있는 메소드들이 정의되어있어 이를 조금만 응용하면 다른 자료구조들 처럼 사용할 수 있다는 것이다.
Stack
popLast() 메소드 이용
Swift의 배열에는 popLast() 라는 메소드가 존재한다.
가장 뒤의 원소를 반환한 후, 제거하는 메소드이기에 이를 사용하면 Stack 자료구조가 딱히 필요없다. ▼
var stack = [String]()
stack.popLast()!
// 가장 뒤의 원소를 반환한 후 제거
조심해야할 점은 배열의 비어있을 때 popLast()가 수행되면 nil을 반환해야하기에 옵셔널 값으로 반환한다.
그래서 nil이 아님을 보장하고, force unwarpping을 해주는 것이 사용하기 편리하다.
아래의 문제에서 이를 응용하면 쉽게 해결할 수 있다. ▼
1918번: 후위 표기식
첫째 줄에 중위 표기식이 주어진다. 단 이 수식의 피연산자는 알파벳 대문자로 이루어지며 수식에서 한 번씩만 등장한다. 그리고 -A+B와 같이 -가 가장 앞에 오거나 AB와 같이 *가 생략되는 등의
www.acmicpc.net
Queue
removeFirst() 메소드 이용
“그러면 큐는 removeFirst로 이를 대체할 수 있겠네요?”
시간이 널널한 문제는 removeFirst()를 통해 해결할 수 있다. ▼
1966번: 프린터 큐
여러분도 알다시피 여러분의 프린터 기기는 여러분이 인쇄하고자 하는 문서를 인쇄 명령을 받은 ‘순서대로’, 즉 먼저 요청된 것을 먼저 인쇄한다. 여러 개의 문서가 쌓인다면 Queue 자료구조에
www.acmicpc.net
18258번: 큐 2
첫째 줄에 주어지는 명령의 수 N (1 ≤ N ≤ 2,000,000)이 주어진다. 둘째 줄부터 N개의 줄에는 명령이 하나씩 주어진다. 주어지는 정수는 1보다 크거나 같고, 100,000보다 작거나 같다. 문제에 나와있지
www.acmicpc.net
하지만 removeFirst()의 시간복잡도는 O(n)이기 때문에 반복적으로 사용하게 되면 시간초과가 날 수 있다.
제거하지 않고 현재의 인덱스만 증가
아래의 문제에서는 BFS큐라고 큐를 사용해야한다. ▼
16234번: 인구 이동
N×N크기의 땅이 있고, 땅은 1×1개의 칸으로 나누어져 있다. 각각의 땅에는 나라가 하나씩 존재하며, r행 c열에 있는 나라에는 A[r][c]명이 살고 있다. 인접한 나라 사이에는 국경선이 존재한다. 모
www.acmicpc.net
백준 16234번 해설 보고 오기 ->
하지만 여기서 removeFirst()를 계속해서 사용하게 되면 시간이 많이 소요될 것이기에 이 문제를 풀 때는 실제로 원소를 제거하는 것이 아닌, 원소를 제거했다고 치고 인덱스만 증가시키는 방식으로 해결했다. ▼
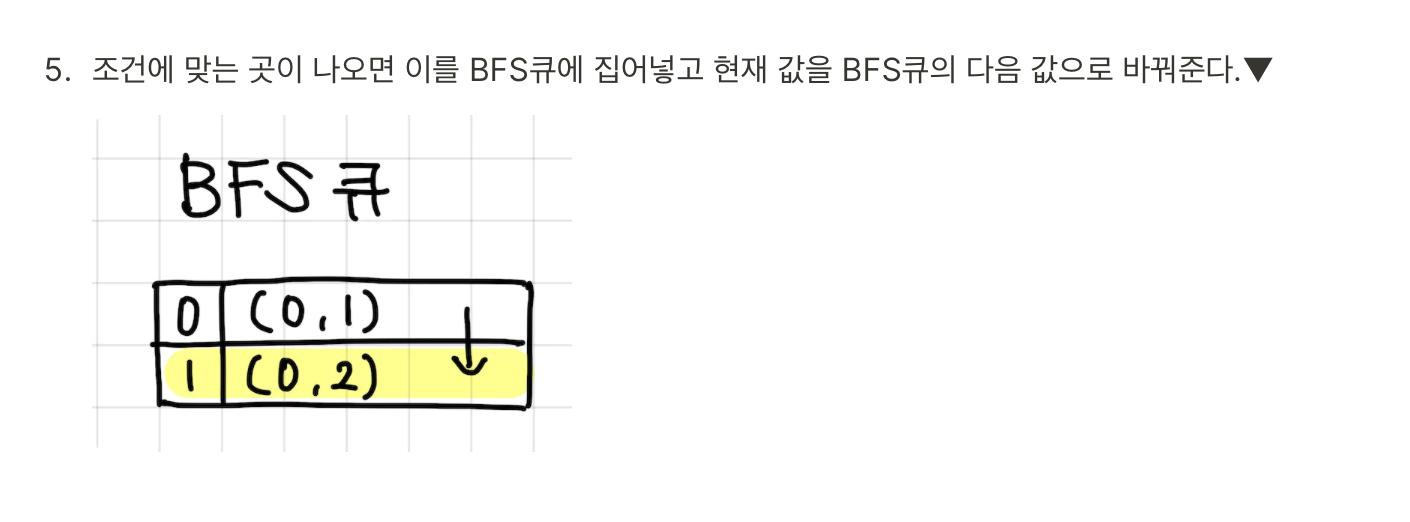
직접 클래스 구현
마지막 방법으로는 직접 클래스를 구현하는 방법이 있다.
아마 이 방법이 제일 귀찮지만 제일 속도가 빠르게 나올 것이다.
그래도 다른 자료구조에 비해 구현하기 쉬운 편이라 생각보다 나쁘지 않은 방법이다.
Deque
덱을 사용해야하는 문제들은 의외로 큐로 해결이 되는 경우가 많다.
그리고 애초에 Swift에는 덱 자료구조가 없기 때문에 앞에서 소개한 방식을 적절하게 사용하면 된다.
스택처럼 뒤의 원소를 뺄 때는 popLast()를, 큐처럼 앞의 원소를 뺄 때는 removeFirst()를 사용하면 된다.
이러다가 removeFirst()의 시간복잡도가 걱정이 된다면, 앞의 큐에서 했던거 처럼 인덱스만 변경하는 방법을 택하거나 클래스를 아예 새롭게 만들면 된다.
Heap
가장 큰 문제인 Heap이다.
최단 경로와 같은 문제에서 Priority Queue가 필요할 때가 있는데, 이 때 Heap이 사용된다. ▼
1753번: 최단경로
첫째 줄에 정점의 개수 V와 간선의 개수 E가 주어진다. (1 ≤ V ≤ 20,000, 1 ≤ E ≤ 300,000) 모든 정점에는 1부터 V까지 번호가 매겨져 있다고 가정한다. 둘째 줄에는 시작 정점의 번호 K(1 ≤ K ≤ V)가
www.acmicpc.net
하지만 Heap은 배열을 사용하는 잡기술로 해결되지 않는다.
그래서 직접 구현을 해야하는데, Heap을 직접 구현하는 건 해볼만 하지만 어떻게 구현하냐에 따라 성능차이가 극심하다.
필자도 구현해서 사용했지만, 최적화의 한계에 부딪혀 시간초과를 많이 경험했다. ▼
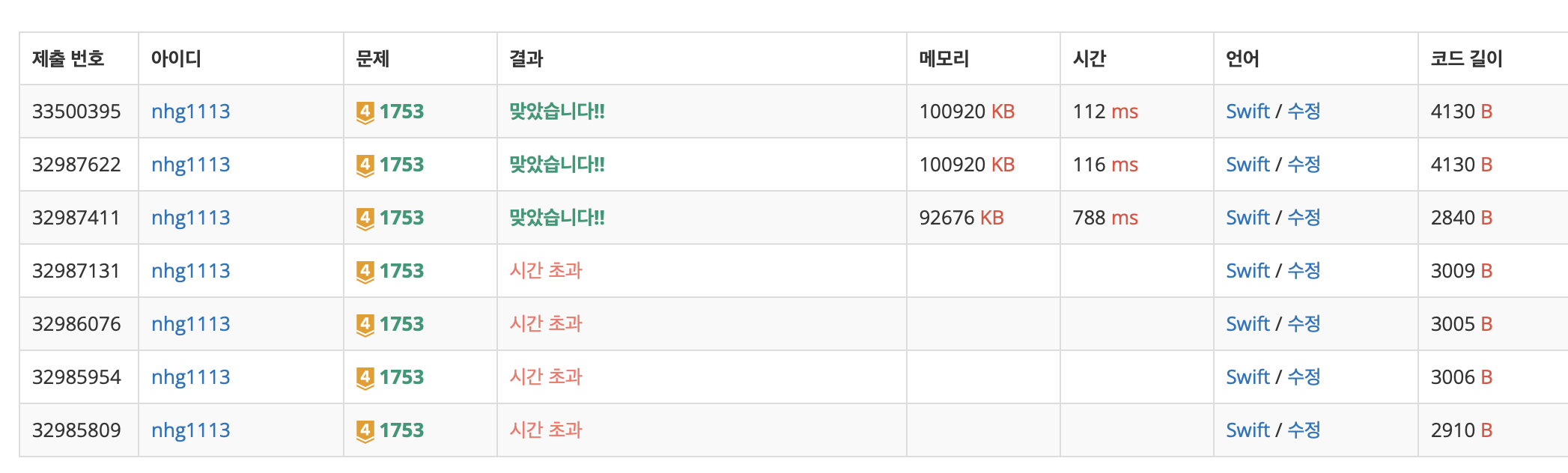
내가 만든 priorityQ로는 이 문제를 넘을 수 없었다. (길이 주의)
struct priorityQ {
var heap = Array(repeating: (0, 0), count: 10000001)
var size = 0
func getParent(_ index: Int) -> (Int, Int) {
return heap[index / 2]
}
func getLeftChild(_ index: Int) -> (Int, Int) {
return heap[index * 2]
}
func getRightChild(_ index: Int) -> (Int, Int) {
return heap[index * 2 + 1]
}
mutating func insert(_ data: (Int, Int)) {
size += 1
var index = size
while index != 1 && data.1 > getParent(index).1 {
heap[index] = getParent(index)
index /= 2
}
heap[index] = data
}
mutating func remove() -> Int {
if heap.isEmpty {
return 0
}
let itemNode = heap[1]
let lastNode = heap[size]
var index = 1
size -= 1
while index <= size {
if index * 2 > size {
break
} else if index * 2 == size {
if lastNode.1 < getLeftChild(index).1 {
heap[index] = getLeftChild(index)
index *= 2
} else {
break
}
} else {
let leftChildKey = getLeftChild(index).1
let rightChildKey = getLeftChild(index).1
if lastNode.1 < leftChildKey || lastNode.1 < rightChildKey {
heap[index] = leftChildKey > rightChildKey ? getLeftChild(index) : getRightChild(index)
index = leftChildKey > rightChildKey ? index * 2 : index * 2 + 1
} else {
break
}
}
}
heap[index] = lastNode
return itemNode.0
}
}
그래서 어쩔 수 없이 또 라이노님께서 구현하신 Heap을 사용하는 것을 추천한다. (길이 주의)
public struct Heap<T> {
var nodes: [T] = []
let comparer: (T,T) -> Bool
var isEmpty: Bool {
return nodes.isEmpty
}
init(comparer: @escaping (T,T) -> Bool) {
self.comparer = comparer
}
func peek() -> T? {
return nodes.first
}
mutating func insert(_ element: T) {
var index = nodes.count
nodes.append(element)
while index > 0, !comparer(nodes[index],nodes[(index-1)/2]) {
nodes.swapAt(index, (index-1)/2)
index = (index-1)/2
}
}
mutating func delete() -> T? {
guard !nodes.isEmpty else {
return nil
}
if nodes.count == 1 {
return nodes.removeFirst()
}
let result = nodes.first
nodes.swapAt(0, nodes.count-1)
_ = nodes.popLast()
var index = 0
while index < nodes.count {
let left = index * 2 + 1
let right = left + 1
if right < nodes.count {
if comparer(nodes[left], nodes[right]),
!comparer(nodes[right], nodes[index]) {
nodes.swapAt(right, index)
index = right
} else if !comparer(nodes[left], nodes[index]){
nodes.swapAt(left, index)
index = left
} else {
break
}
} else if left < nodes.count {
if !comparer(nodes[left], nodes[index]) {
nodes.swapAt(left, index)
index = left
} else {
break
}
} else {
break
}
}
return result
}
}
extension Heap where T: Comparable {
init() {
self.init(comparer: >)
}
}
struct Data : Comparable {
static func < (lhs: Data, rhs: Data) -> Bool {
lhs.cost < rhs.cost
}
var cost : Int
var node : Int
}
“와 이거 넣으면 Heap에 대한 모든 문제는 해결?!”
사용하기 전에 해야할 것이 있다.
아래의 코드를 채워줘야 한다.
// Heap 코드의 마지막 부분
extension Heap where T: Comparable {
init() {
self.init(comparer: >)
}
}
struct Data : Comparable {
static func < (lhs: Data, rhs: Data) -> Bool {
lhs.cost < rhs.cost
}
var cost : Int
var node : Int
}
Heap 정렬 기준인 comparer 매개변수와 Data 구조체를 채워줘야 한다.
Data 구조체의 < 연산자도 오버로딩 해주면 끝이다.
위의 코드처럼 필자가 미리 만들어놓은 대로 사용해도 되는데, 만약에 cost와 node외의 다른 데이터도 필요하게 되면 수정을 해야한다.
이렇게 사용을 하면 Swift에서 자료구조의 대부분은 사용이 가능해진다.
아니 그래도 너무 느린걸요?
이렇게 까지 코드를 최적화하고, 시간이 덜 드는 방법으로 했는데도 시간 초과가 날 때가 있다.
필자는 아래의 문제를 아무리 풀어도 시간초과가 나길래, Swift로는 해결할 수 없는 문제라고 생각했다. ▼
1092번: 배
첫째 줄에 N이 주어진다. N은 50보다 작거나 같은 자연수이다. 둘째 줄에는 각 크레인의 무게 제한이 주어진다. 이 값은 1,000,000보다 작거나 같다. 셋째 줄에는 박스의 수 M이 주어진다. M은 10,000보
www.acmicpc.net
그런데 푼 사람들이 존재했다.
그것도 아주 많이 존재했다. ▼

그래서 맞춘 사람들은 어떻게 맞춘건지 궁금해서 다른 언어로 푼 다음에 코드를 읽어봤는데, 로직이 정말 여기서 더 달라질 수 있을까 싶을 정도로 똑같았다.
내가 뭔가를 잘못 사용한걸까 하고 한 줄씩 다른 사람이 푼 코드로 제출하다가, 결국 전체가 그 사람의 코드로 교체가 된 시점에도 시간초과로 통과받지 못했다.
뭐가 문제였을까 하다가 눈에 들어온 것은 바로 함수였다.
함수로 감싸면 빨라진다?
아래의 글에 작성을 한 내용이지만, 결론은 함수로 감싸면 빨라진다는 것이었다.
이는 파이썬에도 있는 현상이라고 한다. ▼
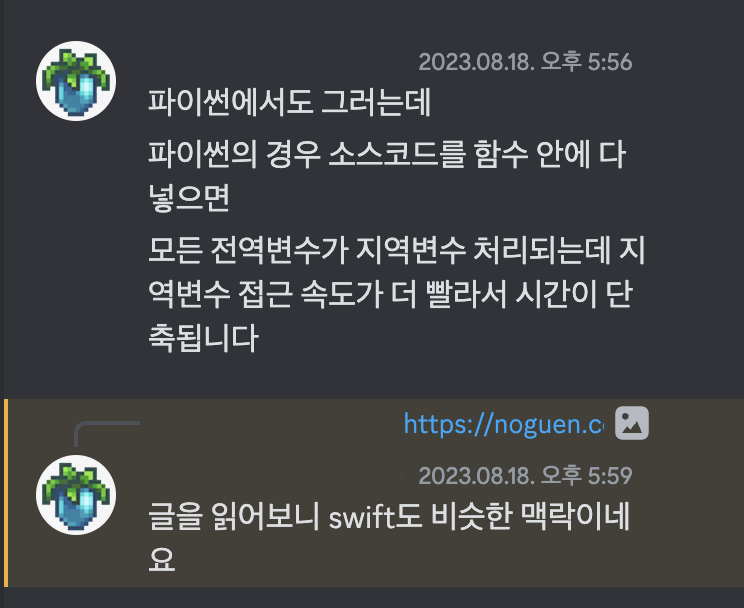
요지는 전역변수보다 지역변수의 접근 속도가 훨씬 빨라서 그런 것이라고 한다.
다른 언어들과 같이 main()와 같은 엔트리 포인트 없이 코드가 실행될 수 있는 Swift와 파이썬에서 전역변수의 속도가 더 느리다는게 조금은 충격이었다.
어쨌거나 이렇게 함수로 감싸서 제출을 하는 것이 시간 단축에 도움이 된다.
그럼 ‘왜’ 함수로 감싸면 빨라질까?
이에 대한 내용으로 아무리 검색을 해도 나오는 내용이 없어서 ChatGPT의 힘을 빌렸다.
chatGPT의 말을 100% 신뢰할 수 있는 것은 아니다.
내용도 21년에 멈춰있고 가끔은 내용을 지어내기 때문에 전적으로 신뢰할 수는 없다.
하지만 이전에 들었던 운영체제 수업과 프로그래밍 언어론에서 배웠던 내용들을 생각해보면 GPT가 하는 말이 완전 틀린 내용이 아니라는 생각이 들었다.
얼추 맞는 내용을 이야기하고 납득 갈 만한 이유들을 이야기하고 있었다.
그리고 위에서 알고리즘 동아리 강사분께서 해주신 내용과 일맥상통하는 것을 보아 대부분 맞는 이야기인거 같다.
이제는 이유도 알았으니 코드를 제출할 때 함수로 감싸서 변수들을 지역변수화 했는지 확인해보자.
마치며
여기까지 Swift로 PS하기 이야기가 끝이 났다.
입출력부터 순회, 자료구조, 그리고 변수 접근 속도 차이까지 다루면서 입문에 필요한 대부분의 내용을 다뤘다.
다른 언어에 비해(특히 파이썬) 알아야 할 게 조금 더 많지만 그럼에도 충분히 매력적인 언어라고 생각한다.
맥이 없으면 온라인 컴파일러밖에 사용할 수 없는게 조금은 아쉽긴 하다.
어쨌거나 여기까지 긴 글 읽어주어 대단히 감사하고 Swift로 즐거운 PS하길 바란다.
화이팅이다!!!
'Algorithm > PS' 카테고리의 다른 글
| 백준 1021번 회전하는 큐 - SWIFT (0) | 2024.02.06 |
|---|---|
| 백준 1019번 책 페이지 - SWIFT (0) | 2024.02.06 |
| 백준 1011번 Fly me to the Alpha Centauri - SWIFT (0) | 2024.02.05 |
| 백준 1092번 배 - SWIFT (0) | 2024.01.20 |
| 백준 16234번 인구 이동 - SWIFT (0) | 2024.01.20 |



